
SEE(Single Event Effect)에 대비한 시스템 설계 및 소프트웨어 구현 방법에 대한 글이다.
SEE란?
표준(IEC 62396-3)에서는 single particle(cosmic rays, solar energetic particles, energetic neutrons and protons)의 영향에 대한 component의 반응이라고 정의되어 있다.
대기중의 방사성 에너지가 digital device에 주입되면, digital device는 energy에 반응하여 여러가지 fault들을 가질 수 있게 된다.
시스템 safety관점에서는 fault는 두 가지로 분류할 수 있다.
- hard – 영향을 받은 LRU(item 혹은 하나의 sub-system정도)의 영구적인 failure가 되도록 하는 fault
- soft – 시스템의 기능이나 redundancy의 손실 없이 복구될 수도 있는 fault
Reliability는 hard fault failure rate의 합으로 결정되며, Availability는 hard fault와 soft fault의 합으로 결정된다.
외부 방사능에 의해 component의 영향 – hard error, soft error, firm error, latch-up, burnout, upset, functional interrupt
hard fault는 방사능에 의해 component가 실제적인 손상이 발생하여 fault가 영구화된 상황을 의미하고, soft fault는 방사능에 의해 일시적으로 발생할 수 있는 fault이며, 이 soft fault가 digital hardware(counter, register, memory 등)의 issue가 된다.
설계상에서 방사능의 영향을 감소(Mitigation)시키는 방법
가장 좋은 것은 방사능에 대한 시험을 통과한 chip을 사면 된다. 젤 비싼 chip으로. 그 부분이 현실적으로 적용하기 곤란한 상황이라면(또한 고객이 굳이 요구하지 않는다면..) 다른 방법을 생각해 볼 수 있다.
시스템을 개발할 때, 3가지 수준에서 SEE를 고려할 수 있다.
- 시스템 아키텍처 단계(system level)
- 시스템 아키텍처 내의 개별 전자 장치의 고려 단계(item or sub-system level)
- 전자 장치의 컴포넌트의 고려 단계(component level)
mitigation 방법 요약
| hard fault | soft fault | |
| system architecture | redundancy | redundancy, monitoring |
| electronic equipment | redundancy | 별도로 표시함. |
| electronic component/device | 우주방사능 시험에 통과된 소자 | error detection, correction 기능이 있는 소자 redundant computing element |
soft fault의 electronic equipment의 mitigation 방법
equipment level에서 손상된 데이터 혹은 에러를 탐지하면 시스템 요구사항에 따라 여러가지 복구 방법이 있을 수 있음. 에러 탐지시 관련 데이터는 다음과 같이 처리될 수 있다.
- faulty로 표시한다.
- 그 데이터는 선택적으로 무시한다.
- 손상되지 않은 redundant module로 switching을 한다.
- 데이터는 삭제하고 좋은 data로부터 영향받은 프로세스를 재초기화한다.
(p.s) ISO 26262 표준 관점에서는 recovery에 대해 recommend를 하지 않은 것으로 봐서 자동차 분야에서는 이 정도까지 Tight하게 요구하지 않는건가? 라고 생각하기는 하지만, detection & correction은 해야 하고, 필요하다면 recovery를 해야 할 수도 있을 것이다.
SEE를 위한 소프트웨어 설계시 고려사항
- parity, CRC, hamming code, reed-solomon code, convolutional code
- watchdog timer, voting
- 보호되지 않은 캐시 메모리의 사용을 최소화
- 주기적으로 캐시를 flushing
- voting을 위해 중요 값을 triple version으로 저장
- 보호 매커니즘이 없는 RAM을 사용하지 않는다. (좋은 RAM을 고른다)
- stack과 heap사용을 최소화한다(동적으로 변경하는 메모리 공간은 소프트웨어에서 보호하기 어려움)
- stack, heap overrun 보호, language에 내장된 protection mechanism사용(ada에서의 variable range check)
- 민감도가 높은(criticality가 높은, 그러니까 문제되면 심각해질 수 있는) 변수의 사용의 최소화
- 주기적으로 중요 영역의 checksum의 수행
- 저장하기 전에 영구적으로 저장되는 공간의 checksum
- transient error를 극복하기 위해 계산을 반복수행
- 상수는 ROM영역에, 만약 RAM에 넣어야 한다면 주기적으로 ROM에서 복사하기
- critical decision/calculation에 사용되는 데이터에 대해서는 RAM 영역이 정확하다고 믿지 말자
- 매 frame마다 하드웨어 latch에 output discrete쓰기
- logic에서 counting을 할 때 ==를 쓰지 않고 >= 나 <=로 하기
- 1부터 30까지 counting을 한다고 했을 때, 메모리 오류가 발생해서 30이라는 숫자에 exact matching되지 않을지도 모름. 그러면 무한 루프에 빠지게 됨
- 소프트웨어에 초기화되는 디바이스의 설정 상태를 지속적으로 점검
- input data를 filter
- BITE나 BIT가 failure를 탐지하면 failure를 confirm하기 위해 재 실행
- bi directional I/O를 사용할 때에는 configuration에 대한 re-assert
- CPU의 설정을 위해 register를 사용할 때, re-assert
- 포인터는 range check
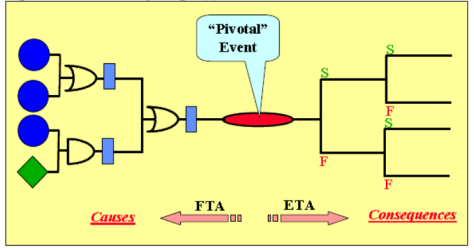 Figure 1. A generic example of Bow-tie model (논문에서 발췌함)
Figure 1. A generic example of Bow-tie model (논문에서 발췌함)